Для чeго это нужно знать?
Хранение и обработка данных — mission-critical задача любой компьютерной системы.
Даже если у вас уже 30 лет есть блог в интернете на текстовых файлах, как у некоторых создателей баз данных бывает, все равно на самом деле этот текстовый файлик — это база данных, только очень простенькая.
Все пытаются изобрести базу данных. Один из докладчиков на конференции сказал: «20 лет назад я написал свою базу данных, только не знал, что это она!» Этот тренд в мире очень развит. Все стараются так делать.
Для работы с данными база данных — это очень удобная штука. Многие базы данных — это очень старые технологии. Они разрабатываются последние полвека, в 70-х годах уже были базы данных, которые работали по схожим принципам, что и сейчас.
Эти базы очень хорошо и продуманно написаны, поэтому теперь мы можем выбрать язык программирования и использовать общий удобный интерфейс обработки данных. Таким образом можно стандартизованно обрабатывать данные, не боясь, что они будут обработаны как-то по-другому.
При этом полезно помнить, что языки программирования меняются: вчера был Python 2, сегодня Python 3, завтра все побежали писать на Go, послезавтра еще на чем-то. У вас может быть кусок кода, который эмулирует работу по манипуляции с данными, которую, по идее, должна делать база данных, а вы не будете знать, что дальше с этим делать.
В большинстве баз данных интерфейс очень консервативный. Если взять PostgreSQL или Oracle, то с некоторым бубном можно работать даже с очень старыми версиями из новых языков программирования — хорошо и здорово.
Но задача на самом деле не самая простая. Если мы начнем закапываться в глубины того, как нам не «побить» данные, как быстро, производительно и, главное так, чтобы потом можно было доверять результату, обрабатывать их, то окажется, что сложное это дело.
Если вы попробуете написать свое простенькое персистентное хранилище, все просто будет только первые 15 минут. Потом начнутся блокировки и прочие вещи, и в какой-то момент вы поймете: «Ой, зачем я все это делаю?»
Об этом и поговорим.
Уровни работы с данными
Итак, есть различные уровни работы с данными:
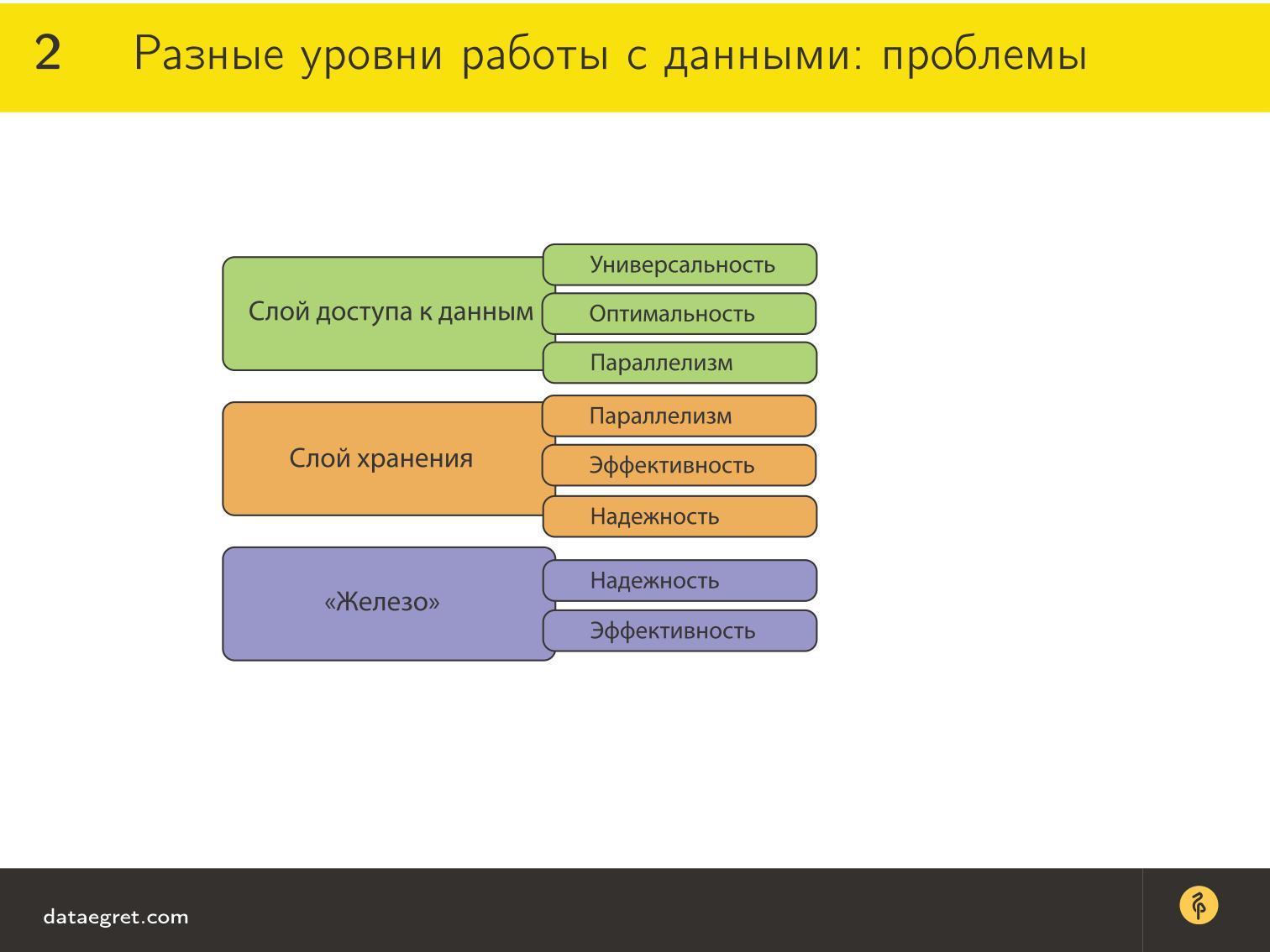
Для слоя доступа к данным есть требования, в выполнении которых мы заинтересованы, чтобы было удобно работать:
В то же время они должны быть надежно сохранены и надежно воспроизведены. То есть, если мы что-то записали в базу данных, мы должны быть уверены, что мы это получим обратно.
Если вы работали со старыми базами данных, например, FoxPro, то знаете, что там часто появляются битые данные. В новых базах данных, типа MongoDB, Cassandra и прочих, такие проблемы тоже случаются. Может быть, просто их не всегда замечают, потому что данных уж очень много и заметить сложнее.
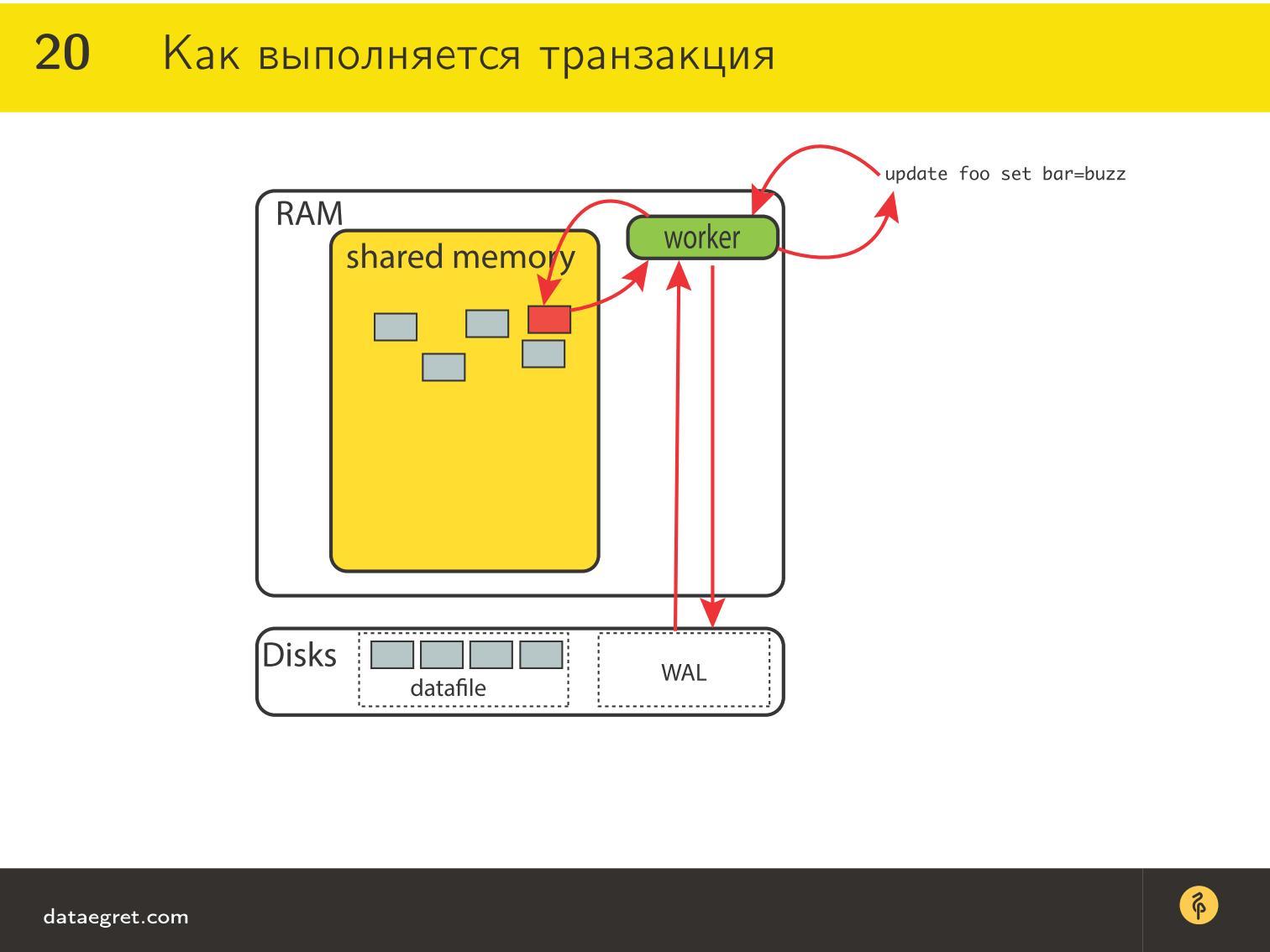
Для «железа» на самом деле важна надежность. Это как бы допущение, поскольку мы все-таки будем говорить о теоретических вещах. В нашей модели, если что-то попало на диск, то мы считаем, что там все хорошо. Как заменить вовремя диск в RAID — это сегодня для нас забота админов. Мы не будем глубоко погружаться в этот вопрос, и практически не будем касаться того, насколько эффективно хранилище организовано физически.
Чтобы решать эти проблемы, есть некоторые подходы, которые очень похожи у разных хранилищ данных — и новых, и классических.
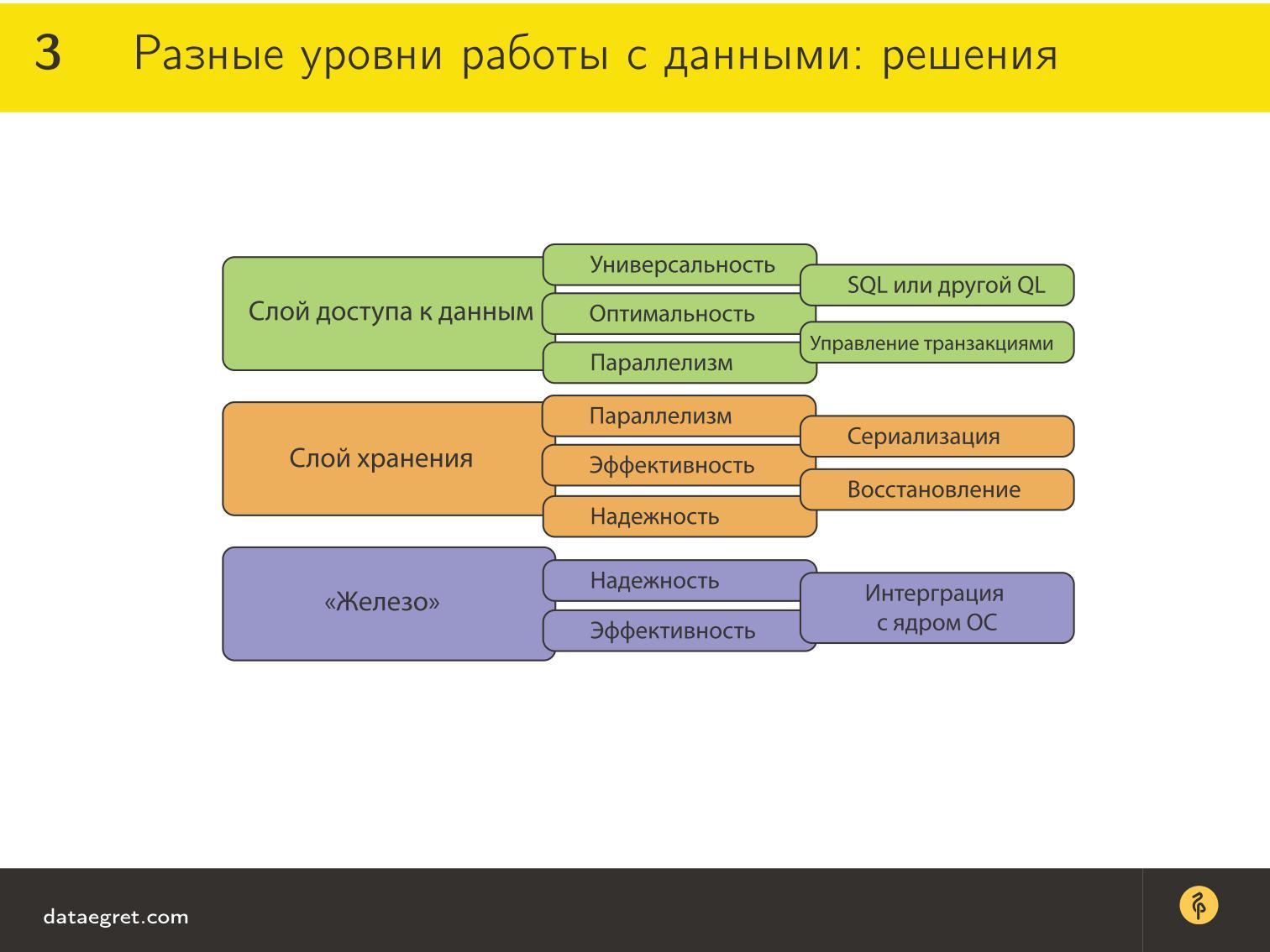
Прежде всего для того, чтобы обеспечить универсальный и оптимальный доступ к данным, есть язык запросов. В большинстве случаев это SQL (почему именно он, мы подискутируем дальше), но сейчас просто хочу обратить внимание на тенденцию. Сначала достаточно долгое время был SQL — конечно, были времена и до него, но, тем не менее, SQL господствовал долго. Потом стали появляться всякие Key-value-storage, которые, дескать, работают без SQL и гораздо лучше.
Многие Key-value-storage в основном делались для того, чтобы из любимого языка программирования было проще ходить за данными, а SQL не очень хорошо вяжется с любимым языком программирования. Он высокоуровневый, декларативный, а нам хочется объектов, поэтому появилась идея, что SQL не нужен.
Но большинство этих технологий сейчас на самом деле придумывают какой-то свой язык запросов. В Hibernate очень развит свой собственный язык запросов, кто-то использует Lua. Даже те, кто раньше использовал Lua, делают свои реализации SQL. То есть сейчас тенденция такая: SQL опять возвращается, потому что удобный человеко-читаемый язык работы со множествами все равно нужен.
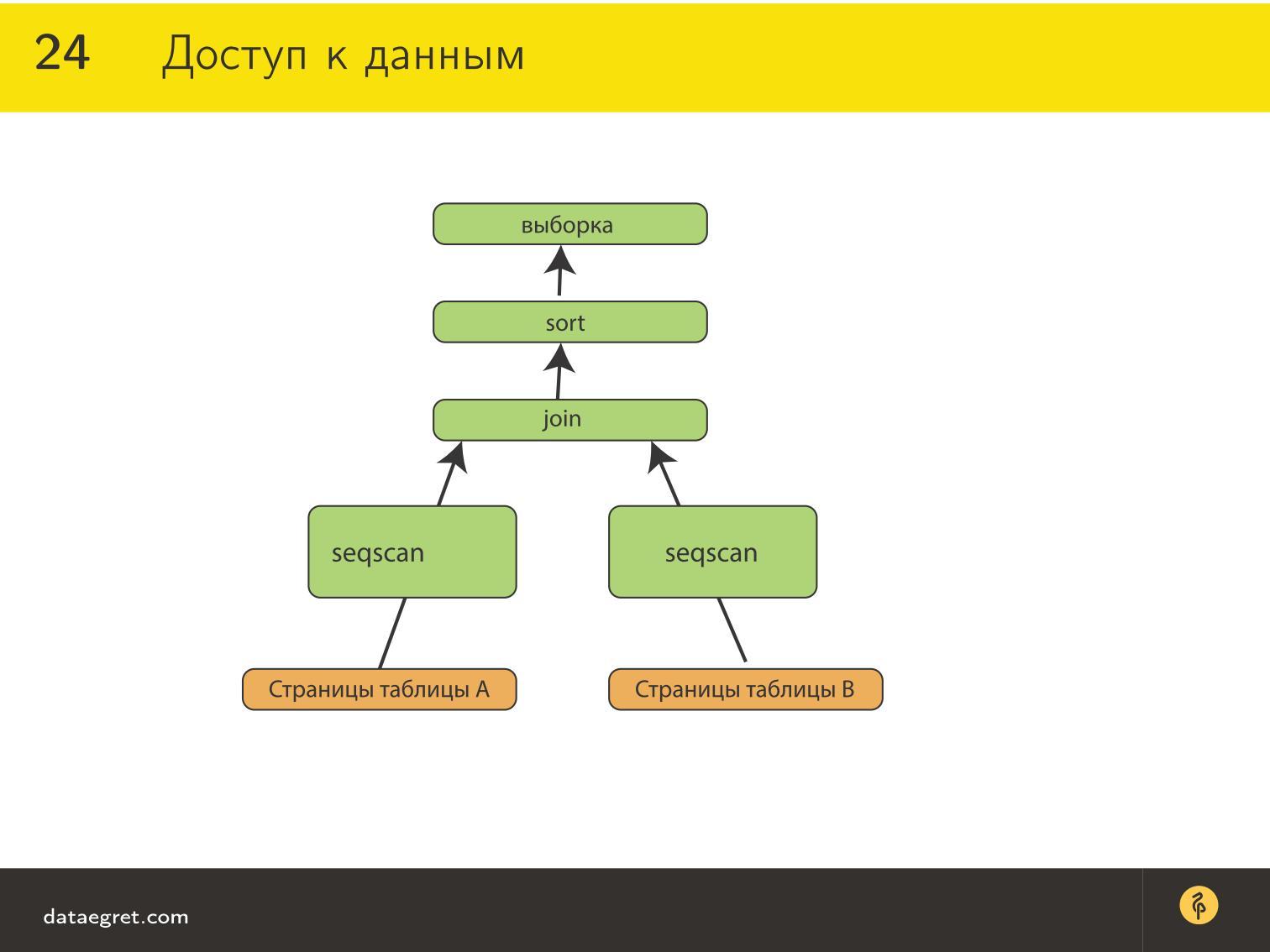
Плюс к тому по-прежнему удобно табличное представление. В той или иной степени во многих базах данных по-прежнему имеются таблички, и это далеко не случайно — таким образом легче оптимизировать запросы. Вся математика оптимизации завязана вокруг реляционной алгебры, и когда есть SQL и таблички, работать гораздо проще.
В слое хранения возникает такое понятие, как сериализация. Когда есть параллелизм и конкурентный доступ, нам нужно обеспечить, чтобы на процессор, на диск это приезжало в более-менее предсказуемом порядке. Для этого нужны алгоритмы сериализации, которые реализуются в слое хранения.
Опять же, если что-то пошло не так и база данных упала, нам нужно ее быстро поднять.
Для этого нужно восстановление, потому что, что ни делай, где-нибудь будет слабое звено и очень большие накладные расходы на синхронизацию. Мы можем сделать сотню копий на сотню серверов, а в результате сгорит питание или какой-то коммутатор, и будет плохо и больно.
Для «железа» на самом деле важно, чтобы база данных была хорошо интегрирована с ОС, работала производительно, вызывала правильные syscalls и поддерживала все фишки ядра по быстрой работе с данными.
Слой хранения
Начнем со слоя хранения. Понимание того, как он устроен, хорошо помогает понять, что происходит на более высоких слоях.
Слой хранения обеспечивает:
✓ Параллелизм и эффективность.
Другими словами, это конкурентный доступ. То есть, когда мы пытаемся получить пользу от параллелизма, неизбежно возникает проблема конкурентного доступа. Мы одновременно ходим за одним ресурсом, который может записаться не так, побиться при записи и, черт знает что еще, может при этом получиться.
✓ Надежность: восстановление после сбоев.
Вторая проблема — это внезапный сбой. Когда обеспечивается надежность, это означает, что мы не только максимально обеспечили катастрофоустойчивое решение, но важно и то, что мы умеем быстро восстановиться в случае чего.
Конкурентный доступ
Когда я говорю о целостности, внешних ключах и прочем, все как-то хмыкают и говорят, что все это они проверяют на уровне кода. Но как только предложишь: «А давайте пример на вашей зарплате! Вам переводят зарплату, а она не пришла», — почему-то сразу понятней становится. Не знаю почему, но сразу появляется блеск в глазах и интерес к теме внешних ключей, констрейнтов.
Ниже код на несуществующем языке программирования.
account_a {
balance = 1000,
curr = ’RUR’
}
send_money(account_a, account_b, 100);
send_money(account_a, account_c, 200);
account_a->balance = ???
Допустим, у нас есть банковский счет с балансом в 1 000 рублей, и есть 2 функции. Как они устроены внутри, нам сейчас не важно, эти функции переводят с аккаунта a на другие банковские счета 100 и 200 рублей.
Внимание, вопрос: сколько денег окажется в результате на балансе счета a? Скорее всего, вы ответите, что 700.
Проблемы
Здесь начинаются проблемы с конкурентным доступом к данным, потому что язык у меня выдуманный, совершенно не понятно, как он реализован, одновременно ли исполняются эти функции и как они устроены внутри.
Мы, наверное, считаем, что операция send_money() — это не элементарное действие. Надо проверить баланс и куда переводится, выполнить контроль 1 и 2. Это не элементарные операции, которые занимают какое-то время. поэтому нам важен порядок выполнения элементарных операций внутри них.
В последовательности «прочитали значение на балансе», «записали на другой баланс», важен вопрос — когда мы читали этот баланс? Если мы это делаем одновременно, возникнет конфликт. Обе функции выполняются примерно параллельно: прочитали одно и то же значение баланса, перевели деньги, записали каждая свое.
Может возникнуть целое семейство конфликтов, в результате которых на балансе может оказаться 800 рублей, 700 рублей, как должно быть, или что-то побьется, и на балансе окажется null. Такое, к сожалению, бывает, если не относиться к этому с должным вниманием. Как с этим бороться, мы и поговорим.
В теории все просто — мы можем выполнить их одну за другой и все будет хорошо. На практике этих операций может быть очень много и делать их строго последовательно может быть проблематично.
Если помните, несколько лет назад была история, когда у Сбербанка упал Oracle и процессинг карточек остановился. Они тогда просили совета у общественности и примерно обозначили, сколько логов писала база данных писала. Это огромные количества и конкурентные проблемы.
Выполнять операции строго последовательно не очень хорошая идея еще и по той простой причине, что операций много, а мы ничего не выиграем от параллелизма. Можно, конечно, разбивать операции по группам, которые не будут конфликтовать друг с другом. Такие подходы тоже есть, но они не очень классические для современных баз данных.
Хранение и обработка данных — mission-critical задача любой компьютерной системы.
Даже если у вас уже 30 лет есть блог в интернете на текстовых файлах, как у некоторых создателей баз данных бывает, все равно на самом деле этот текстовый файлик — это база данных, только очень простенькая.
Все пытаются изобрести базу данных. Один из докладчиков на конференции сказал: «20 лет назад я написал свою базу данных, только не знал, что это она!» Этот тренд в мире очень развит. Все стараются так делать.
Для работы с данными база данных — это очень удобная штука. Многие базы данных — это очень старые технологии. Они разрабатываются последние полвека, в 70-х годах уже были базы данных, которые работали по схожим принципам, что и сейчас.
Эти базы очень хорошо и продуманно написаны, поэтому теперь мы можем выбрать язык программирования и использовать общий удобный интерфейс обработки данных. Таким образом можно стандартизованно обрабатывать данные, не боясь, что они будут обработаны как-то по-другому.
При этом полезно помнить, что языки программирования меняются: вчера был Python 2, сегодня Python 3, завтра все побежали писать на Go, послезавтра еще на чем-то. У вас может быть кусок кода, который эмулирует работу по манипуляции с данными, которую, по идее, должна делать база данных, а вы не будете знать, что дальше с этим делать.
В большинстве баз данных интерфейс очень консервативный. Если взять PostgreSQL или Oracle, то с некоторым бубном можно работать даже с очень старыми версиями из новых языков программирования — хорошо и здорово.
Но задача на самом деле не самая простая. Если мы начнем закапываться в глубины того, как нам не «побить» данные, как быстро, производительно и, главное так, чтобы потом можно было доверять результату, обрабатывать их, то окажется, что сложное это дело.
Если вы попробуете написать свое простенькое персистентное хранилище, все просто будет только первые 15 минут. Потом начнутся блокировки и прочие вещи, и в какой-то момент вы поймете: «Ой, зачем я все это делаю?»
Об этом и поговорим.
Уровни работы с данными
Итак, есть различные уровни работы с данными:
- Слой доступа к данным, который удобно использовать из языков программирования;
- Слой хранения. Это отдельный слой, потому что обычно хранить данные удобно другими способами, чем использовать: эффективно по памяти, выравнивать, складывать на диск. Это к вопросу о schemaless: схема, которая удобна для хранения, не удобна для доступа.
- «Железо» — слой, где лежат данные, причем там они организованы еще третьим способом, потому что дисками управляет операционная система, и общаются они только через драйвер. В этот уровень мы не будем сильно вникать.
Для слоя доступа к данным есть требования, в выполнении которых мы заинтересованы, чтобы было удобно работать:
- Универсальность, чтобы возможно было с помощью любой технологии запрашивать данные.
- Оптимальность этого запроса. Метод доступа должен быть такой, чтобы хорошо и удобно доставать данные из базы.
- Параллелизм, потому что сейчас все масштабируются, разные серверы одновременно обращаются к базу за одними и теми же данными. Надо сделать так, чтобы максимально использовать преимущества параллелизма и быстрее обрабатывать данные таким способом.
В то же время они должны быть надежно сохранены и надежно воспроизведены. То есть, если мы что-то записали в базу данных, мы должны быть уверены, что мы это получим обратно.
Если вы работали со старыми базами данных, например, FoxPro, то знаете, что там часто появляются битые данные. В новых базах данных, типа MongoDB, Cassandra и прочих, такие проблемы тоже случаются. Может быть, просто их не всегда замечают, потому что данных уж очень много и заметить сложнее.
Для «железа» на самом деле важна надежность. Это как бы допущение, поскольку мы все-таки будем говорить о теоретических вещах. В нашей модели, если что-то попало на диск, то мы считаем, что там все хорошо. Как заменить вовремя диск в RAID — это сегодня для нас забота админов. Мы не будем глубоко погружаться в этот вопрос, и практически не будем касаться того, насколько эффективно хранилище организовано физически.
Чтобы решать эти проблемы, есть некоторые подходы, которые очень похожи у разных хранилищ данных — и новых, и классических.
Прежде всего для того, чтобы обеспечить универсальный и оптимальный доступ к данным, есть язык запросов. В большинстве случаев это SQL (почему именно он, мы подискутируем дальше), но сейчас просто хочу обратить внимание на тенденцию. Сначала достаточно долгое время был SQL — конечно, были времена и до него, но, тем не менее, SQL господствовал долго. Потом стали появляться всякие Key-value-storage, которые, дескать, работают без SQL и гораздо лучше.
Многие Key-value-storage в основном делались для того, чтобы из любимого языка программирования было проще ходить за данными, а SQL не очень хорошо вяжется с любимым языком программирования. Он высокоуровневый, декларативный, а нам хочется объектов, поэтому появилась идея, что SQL не нужен.
Но большинство этих технологий сейчас на самом деле придумывают какой-то свой язык запросов. В Hibernate очень развит свой собственный язык запросов, кто-то использует Lua. Даже те, кто раньше использовал Lua, делают свои реализации SQL. То есть сейчас тенденция такая: SQL опять возвращается, потому что удобный человеко-читаемый язык работы со множествами все равно нужен.
Плюс к тому по-прежнему удобно табличное представление. В той или иной степени во многих базах данных по-прежнему имеются таблички, и это далеко не случайно — таким образом легче оптимизировать запросы. Вся математика оптимизации завязана вокруг реляционной алгебры, и когда есть SQL и таблички, работать гораздо проще.
В слое хранения возникает такое понятие, как сериализация. Когда есть параллелизм и конкурентный доступ, нам нужно обеспечить, чтобы на процессор, на диск это приезжало в более-менее предсказуемом порядке. Для этого нужны алгоритмы сериализации, которые реализуются в слое хранения.
Опять же, если что-то пошло не так и база данных упала, нам нужно ее быстро поднять.
Как вы считаете, можно ли написать 100% надежное отказоустойчивое хранилище? Наверное, вы знаете, что база данных надежно работает только тогда, когда есть механизм, чтобы ее быстро поднять, если она упала.
Для этого нужно восстановление, потому что, что ни делай, где-нибудь будет слабое звено и очень большие накладные расходы на синхронизацию. Мы можем сделать сотню копий на сотню серверов, а в результате сгорит питание или какой-то коммутатор, и будет плохо и больно.
Для «железа» на самом деле важно, чтобы база данных была хорошо интегрирована с ОС, работала производительно, вызывала правильные syscalls и поддерживала все фишки ядра по быстрой работе с данными.
Слой хранения
Начнем со слоя хранения. Понимание того, как он устроен, хорошо помогает понять, что происходит на более высоких слоях.
Слой хранения обеспечивает:
✓ Параллелизм и эффективность.
Другими словами, это конкурентный доступ. То есть, когда мы пытаемся получить пользу от параллелизма, неизбежно возникает проблема конкурентного доступа. Мы одновременно ходим за одним ресурсом, который может записаться не так, побиться при записи и, черт знает что еще, может при этом получиться.
✓ Надежность: восстановление после сбоев.
Вторая проблема — это внезапный сбой. Когда обеспечивается надежность, это означает, что мы не только максимально обеспечили катастрофоустойчивое решение, но важно и то, что мы умеем быстро восстановиться в случае чего.
Конкурентный доступ
Когда я говорю о целостности, внешних ключах и прочем, все как-то хмыкают и говорят, что все это они проверяют на уровне кода. Но как только предложишь: «А давайте пример на вашей зарплате! Вам переводят зарплату, а она не пришла», — почему-то сразу понятней становится. Не знаю почему, но сразу появляется блеск в глазах и интерес к теме внешних ключей, констрейнтов.
Ниже код на несуществующем языке программирования.
account_a {
balance = 1000,
curr = ’RUR’
}
send_money(account_a, account_b, 100);
send_money(account_a, account_c, 200);
account_a->balance = ???
Допустим, у нас есть банковский счет с балансом в 1 000 рублей, и есть 2 функции. Как они устроены внутри, нам сейчас не важно, эти функции переводят с аккаунта a на другие банковские счета 100 и 200 рублей.
Внимание, вопрос: сколько денег окажется в результате на балансе счета a? Скорее всего, вы ответите, что 700.
Проблемы
Здесь начинаются проблемы с конкурентным доступом к данным, потому что язык у меня выдуманный, совершенно не понятно, как он реализован, одновременно ли исполняются эти функции и как они устроены внутри.
Мы, наверное, считаем, что операция send_money() — это не элементарное действие. Надо проверить баланс и куда переводится, выполнить контроль 1 и 2. Это не элементарные операции, которые занимают какое-то время. поэтому нам важен порядок выполнения элементарных операций внутри них.
В последовательности «прочитали значение на балансе», «записали на другой баланс», важен вопрос — когда мы читали этот баланс? Если мы это делаем одновременно, возникнет конфликт. Обе функции выполняются примерно параллельно: прочитали одно и то же значение баланса, перевели деньги, записали каждая свое.
Может возникнуть целое семейство конфликтов, в результате которых на балансе может оказаться 800 рублей, 700 рублей, как должно быть, или что-то побьется, и на балансе окажется null. Такое, к сожалению, бывает, если не относиться к этому с должным вниманием. Как с этим бороться, мы и поговорим.
В теории все просто — мы можем выполнить их одну за другой и все будет хорошо. На практике этих операций может быть очень много и делать их строго последовательно может быть проблематично.
Если помните, несколько лет назад была история, когда у Сбербанка упал Oracle и процессинг карточек остановился. Они тогда просили совета у общественности и примерно обозначили, сколько логов писала база данных писала. Это огромные количества и конкурентные проблемы.
Выполнять операции строго последовательно не очень хорошая идея еще и по той простой причине, что операций много, а мы ничего не выиграем от параллелизма. Можно, конечно, разбивать операции по группам, которые не будут конфликтовать друг с другом. Такие подходы тоже есть, но они не очень классические для современных баз данных.